操作系统之内存管理
内存管理的需求
重定位
为什么需要重定位?有两个原因:
- 多个进程同时在内存中,互相 “挤兑”,地址无法事先确定。
- 活动进程需要换入换出内存,如果地址换入还要保持先前相同的地址,这会是一个极大的限制。
因此,操作系统必须能够以某种方式把程序代码中的内存访问(逻辑地址)转换成实际的物理地址,并反映程序在内存中的位置,也就是具备重定位的能力。
保护
进程必须受到保护,避免其他进程非法读写自己的内存单元。并且,由于重定位,无疑增加保护的难度。因为程序在内存中的位置是不可预测的,一次编译时不可能通过查绝对地址来确保保护。并且,大多数程序语言允许运行时进行地址的动态计算(如数组下标和指针)。因此,必须在运行时检查进程所有的内存访问,确保进程不会越界访问。
注意:内存保护的需要必须由处理器(硬件)来满足,而不是由操作系统(软件)来满足,只是因为操作系统不能预测程序可能产生的所有内存访问;即使可以预测,提前审查每个进程中存在的违法访问也是非常费时的。所以,处理器必须具备保护的能力。
共享
多个进程正在执行同一程序,那就内存中只保存一份,让它们共享吧
逻辑组织
主要体现在分段技术上,后面分析。

物理组织
操作系统存储器物理上分为两级,内存和外存。在这两级存储器间移动信息的任务就是操作系统的责任了,这就是存储管理的本质。(总不让程序员编程时内存不足去换入换出或者覆盖吧 )
内存分区
| 技术 | 说明 | 优点 | 缺点 |
|---|---|---|---|
| 固定分区 | 内存被划分成许多静态分区 | 简单,开销低 | 有内部碎片、内存使用不充分,活动进程最大数目是固定的 |
| 动态分区 | 根据进程大小动态创建分区 | 没有内部碎片,充分利用内存 | 需要压碎外部碎片,处理器利用率低 |
| 简单分页 | 内存被分为大小相等的页框,每个进程被分成许多大小与页框相等的页,把进程包含的页装入到内存内不一定连续的某些页框中。 | 没有外部碎片 | 少量内部碎片 |
| 简单分段 | 每个进程被划分成许多段,要装入一个进程,需要把进程包含的所有段都装入到不一定连续的动态分区中 | 没有内部碎片,相对于动态分区,提高了内存利用率,减少了开销 | 存在外部碎片 |
| 虚拟内存分页 | 不需要装入一个进程的所有页,非驻留页在需要的时候自动调入 | 没有外部碎片,支持更高道数的多道程序设计,巨大的虚拟内存空间 | 复杂的内存管理开销 |
| 虚拟内存分段 | 不需要装入一个进程的所有段,非驻留段在需要的时候自动调入 | 没有内部碎片,支持更高道数的多道程序设计,巨大的虚拟内存空间,支持保护和共享 | 复杂的内存管理开销 |
| 虚拟内存段页 | 用户空间分为段,段划分成固定页,页的长度等于页框大小。 | 具有两者的优点 | 复杂性和开销增加。硬件以及占用的内存增加,执行速度下降。 |
为了支持多道程序系统和分时系统,支持多个程序并发执行,引入了分区式存储管理。分区式存储管理是把内存分为一些大小相等或不等的分区,操作系统占用其中一个分区,其余的分区由应用程序使用,每个应用程序占用一个或几个分区。分区式存储管理虽然可以支持并发,但难以进行内存分区的共享。
分区式存储管理引人了两个新的问题:内碎片和外碎片。
内碎片是占用分区内未被利用的空间,外碎片是占用分区之间难以利用的空闲分区(通常是小空闲分区)。
为实现分区式存储管理,操作系统应维护的数据结构为分区表或分区链表。表中各表项一般包括每个分区的起始地址、大小及状态(是否已分配)。
分区式存储管理常采用的一项技术就是**内存紧缩(compaction)。**
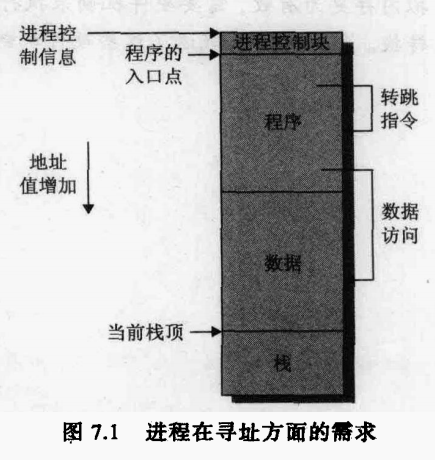
固定分区(nxedpartitioning)
固定式分区的特点是把内存划分为若干个固定大小的连续分区。分区大小可以相等:这种作法只适合于多个相同程序的并发执行(处理多个类型相同的对象)。分区大小也可以不等:有多个小分区、适量的中等分区以及少量的大分区。根据程序的大小,分配当前空闲的、适当大小的分区。
优点:易于实现,开销小。
\缺点主要有两个**:内碎片造成浪费;分区总数固定,限制了并发执行的程序数目。
动态分区(dynamic partitioning)
动态分区的特点是动态创建分区:在装入程序时按其初始要求分配,或在其执行过程中通过系统调用进行分配或改变分区大小。与固定分区相比较其优点是:没有内碎片。但它却引入了另一种碎片——外碎片。动态分区的分区分配就是寻找某个空闲分区,其大小需大于或等于程序的要求。若是大于要求,则将该分区分割成两个分区,其中一个分区为要求的大小并标记为“占用”,而另一个分区为余下部分并标记为“空闲”。分区分配的先后次序通常是从内存低端到高端。动态分区的分区释放过程中有一个要注意的问题是,将相邻的空闲分区合并成一个大的空闲分区。
下面列出了几种常用的分区分配算法:
首次适配法(nrst-fit):按分区在内存的先后次序从头查找,找到符合要求的第一个分区进行分配。该算法的分配和释放的时间性能较好,较大的空闲分区可以被保留在内存高端。但随着低端分区不断划分会产生较多小分区,每次分配时查找时间开销便会增大。
下次适配法(循环首次适应算法 next fit):按分区在内存的先后次序,从上次分配的分区起查找(到最后{区时再从头开始},找到符合要求的第一个分区进行分配。该算法的分配和释放的时间性能较好,使空闲分区分布得更均匀,但较大空闲分区不易保留。
最佳适配法(best-fit):按分区在内存的先后次序从头查找,找到其大小与要求相差最小的空闲分区进行分配。从个别来看,外碎片较小;但从整体来看,会形成较多外碎片优点是较大的空闲分区可以被保留。
最坏适配法(worst- fit):按分区在内存的先后次序从头查找,找到最大的空闲分区进行分配。基本不留下小空闲分区,不易形成外碎片。但由于较大的空闲分区不被保留,当对内存需求较大的进程需要运行时,其要求不易被满足。
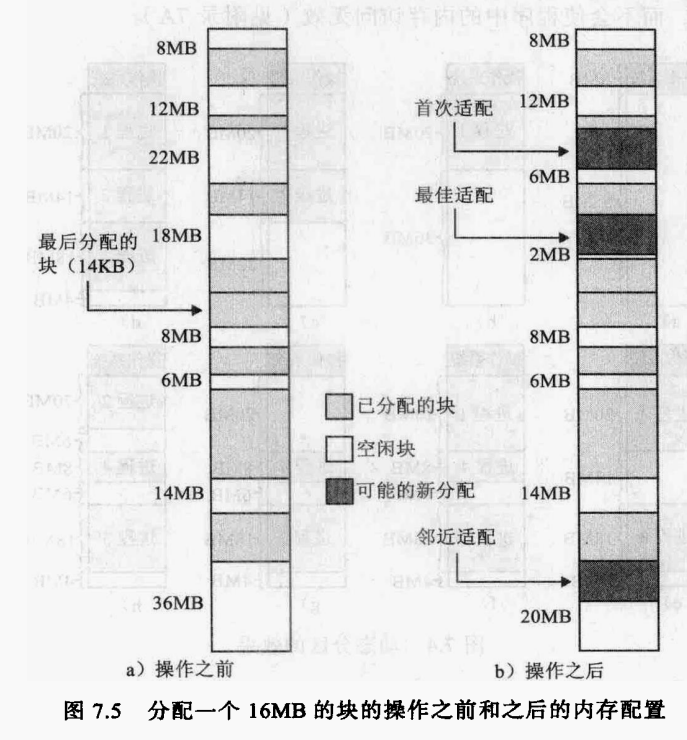
图7.5a给出了经过多次放置和换出操作之后内存配置的例子。前一次操作在一个22MB的块中建了一个14MB的分区。图7.5b给出了为满足一个16MB的分配请求,使用最佳适配,首次适配和下次适配三种放置算法的区别。最佳适配査找所有的可用块列表,最后使用了一个的8MB的块,留下了2MB的碎片;首次适配产生了一个6MB的碎片;下次适配产生了一个20MB的碎片。
各种方法的好坏取决于发生进程交换的次序以及这些进程的大小。首次适配算法不仅是最简单的,而且通常也是最好和最快的。下次适配算法通常比首次适配的结果要差,它常常会导致在内存的末尾分配空间,导致的结果是通常位于存储空间未尾的最大空闲存储块很快被分裂成小碎片。因此使用下次适配算法可能需要更多次数的压缩。另ー方面,首次适配算法会使得内存的前端出现很多小的空闲分区,并且每当进行首次适配查找时,都要经过这些分区。最佳适配算法尽管称为“最佳”,但通常性能却是最差的。这个算法要查找满足要求的最小块,因面它可能保证产生的碎片尽可能地小。尽管每次存储请求总是浪费最小的存储空间,但结果却使得内存中很快产生许多。
伙伴系统
固定分区和动态分区方式都有不足之处。固定分区方式限制了活动进程的数目,当进程大小与空闲分区大小不匹配时,内存空间利用率很低。动态分区方式算法复杂,回收空闲分区时需要进行分区合并等,系统开销较大。伙伴系统方式是对以上两种内存方式的一种折衷方案。
伙伴系统规定,无论已分配分区或空闲分区,其大小均为 2 的 k 次幂,k 为整数, l≤k≤m,其中:
2^1 表示分配的最小分区的大小,
2^m 表示分配的最大分区的大小,
通常 2^m是整个可分配内存的大小。
假设系统的可利用空间容量为2^m个字, 则系统开始运行时, 整个内存区是一个大小为2^m的空闲分区。在系统运行过中, 由于不断的划分,可能会形成若干个不连续的空闲分区,将这些空闲分区根据分区的大小进行分类,对于每一类具有相同大小的所有空闲分区,单独设立一个空闲分区双向链表。这样,不同大小的空闲分区形成了k(0≤k≤m)个空闲分区链表。
\分配步骤:**
当需要为进程分配一个长度为n 的存储空间时:
首先计算一个i 值,使 2^(i-1) <n ≤ 2^i,
然后在空闲分区大小为2^i的空闲分区链表中查找。
若找到,即把该空闲分区分配给进程。
否则,表明长度为2^i的空闲分区已经耗尽,则在分区大小为2^(i+1)的空闲分区链表中寻找。
若存在 2^(i+1)的一个空闲分区,则把该空闲分区分为相等的两个分区,**这两个分区称为一对伙伴,**其中的一个分区用于配, 而把另一个加入分区大小为2^i的空闲分区链表中。
若大小为2^(i+1)的空闲分区也不存在,则需要查找大小为2^(i+2)的空闲分区, 若找到则对其进行两次分割:
第一次,将其分割为大小为 2^(i+1)的两个分区,一个用于分配,一个加入到大小为 2^(i+1)的空闲分区链表中;
第二次,将第一次用于分配的空闲区分割为 2^i的两个分区,一个用于分配,一个加入到大小为 2^i的空闲分区链表中。
若仍然找不到,则继续查找大小为 2^(i+3)的空闲分区,以此类推。
由此可见,在最坏的情况下,可能需要对 2^k的空闲分区进行 k 次分割才能得到所需分区。
与一次分配可能要进行多次分割一样,一次回收也可能要进行多次合并,如回收大小为2^i的空闲分区时,若事先已存在2^i的空闲分区时,则应将其与伙伴分区合并为大小为2^i+1的空闲分区,若事先已存在2^i+1的空闲分区时,又应继续与其伙伴分区合并为大小为2^i+2的空闲分区,依此类推。
在伙伴系统中,其分配和回收的时间性能取决于查找空闲分区的位置和分割、合并空闲分区所花费的时间。与前面所述的多种方法相比较,由于该算法在回收空闲分区时,需要对空闲分区进行合并,所以其时间性能比前面所述的分类搜索算法差,但比顺序搜索算法好,而其空间性能则远优于前面所述的分类搜索法,比顺序搜索法略差。 需要指出的是,在当前的操作系统中,普遍采用的是下面将要讲述的基于分页和分段机制的虚拟内存机制,该机制较伙伴算法更为合理和高效,但在多处理机系统中,伙伴系统仍不失为一种有效的内存分配和释放的方法,得到了大量的应用。
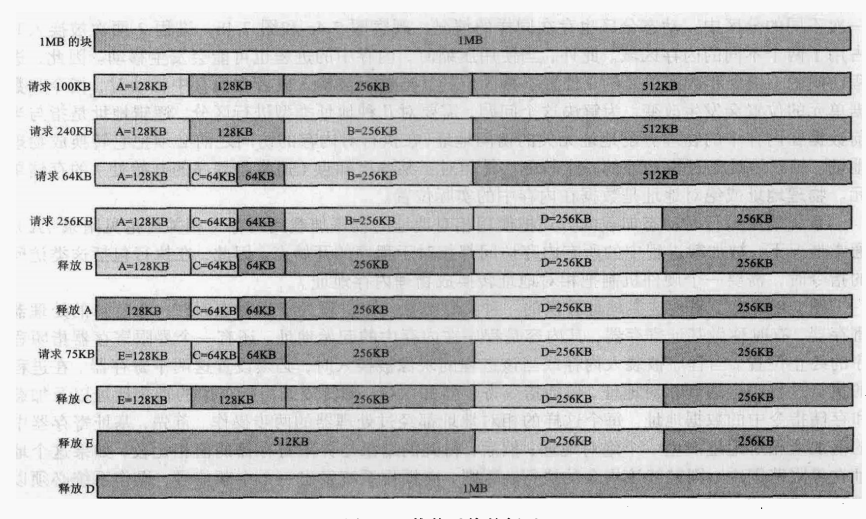
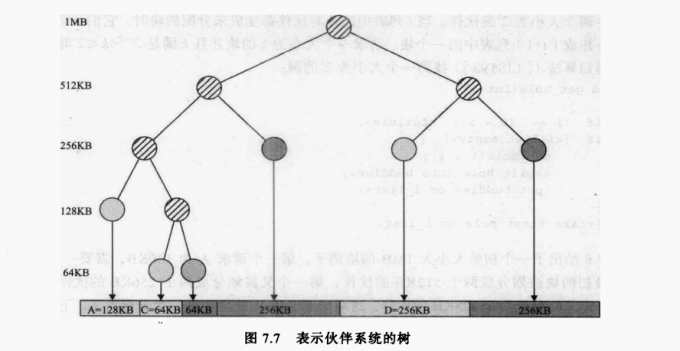
图7.6给出了一个初始大小为1MB的块例子。第一个请求A为100KB,需要一个128KB的块。最初的块被划分成两个512KB的伙伴,第一个又被划分成两个256KB的伙伴,并且其中的第一个又划分成两个128KB的伙伴这两个128KB的伙伴中的一个分配给A。下一个请求B需要256KB的块,因为已经有这样的一个块,随即分配给它。在需要时,这个分裂和合并的过程继续进行。注意,当E被释放时两个128KB的伙伴合并成一个256KB的块,这个256KB的块又立即与它的伙伴合并成一个512KB的块。
图7.7给出了一个表示当释放B的请求后的伙伴系统分配情况的二叉树。叶节点表示内存中的当前分区,如果两个伙伴都是叶节点,则至少有一个必须已经被分配出去了,否则它们将合并成一个更大的块。
分页
实际上存储在物理内存上(磁盘上),运行时一页一页读取;
1.基本思想
用户程序的地址空间被划分成若干固定大小的区域,称为“页”,相应地,内存空间分成若干个物理块,页和块的大小相等。可将用户程序的任一页放在内存的任一块中,实现了离散分配。
等分内存
页式存储管理将内存空间划分成等长的若干物理块,成为物理页面也成为物理块,每个物理块的大小一般取2的整数幂。内存的所有物理块从0开始编号,称作物理页号。
逻辑地址
系统将程序的逻辑空间按照同样大小也划分成若干页面,称为逻辑页面也称为页。程序的各个逻辑页面从0开始依次编号,称作逻辑页号或相对页号。每个页面内从0开始编址,称为页内地址。程序中的逻辑地址由两部分组成:页号P和页内位移量W。
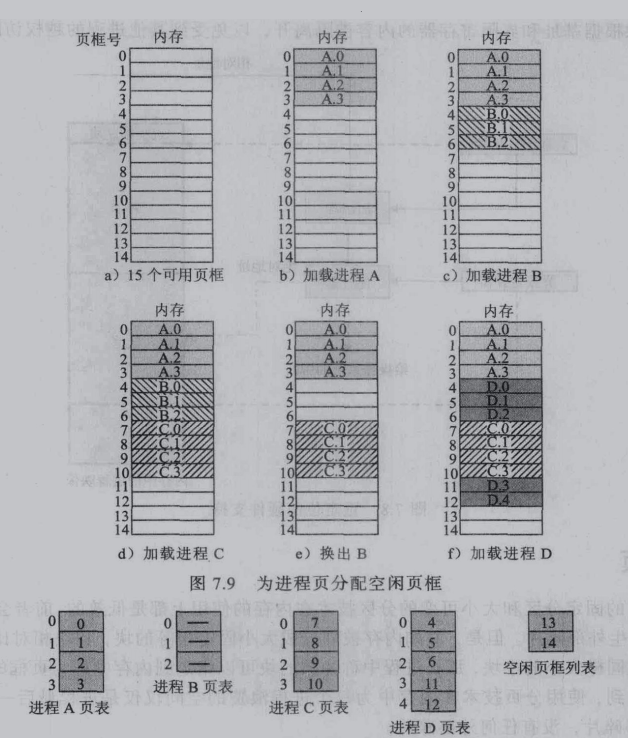
在执行一个程序之前,内存管理器需要的准备工作:
确定程序的页数
在主存中留出足够的空闲页面
将程序的所有页面载入主存里。(静态的分页,页面无需连续)
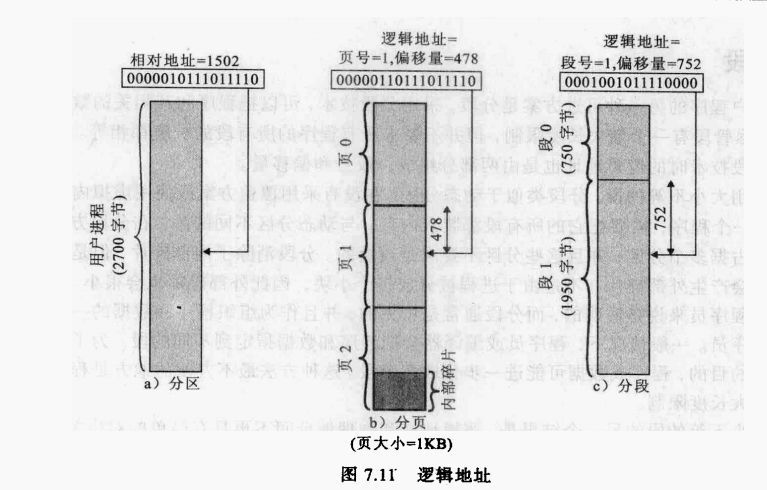
为了使分页方案更加方便,规定页的大小以及页框的大小必须是2的幂,以便容易地表示出相对地址。相对地址由程序的起点和逻辑地址定义,可以用页号和偏移量表示。图7.11给出了个例子,这里使用的是16位地址,页大小为1KB,即1024字节。例如相对地址1502的二进制形式为00000111010由于页大小为1KB,偏移量为10位,剩下的6位为页号,因此,一个程序最多由2^6=64页组成,每页为1KB。如图7.11b所示,相对地址1502对应于页1(000001)中的偏移量478(0111011110),它们可以产生相同的16位数0000010111011110
使用页大小为2的的页的结果是双重的。首先,逻辑地址方案对编程者、汇编器和链接器是透明的。程序的每个逻辑地址(页号,偏移量)与它的相对地址是一致的。其次,用硬件实现运行时动态地址转换的功能相对比较容易。考虑一个n+m位的地址,最左边的n位是页号,最右边的m位是偏移量。在图7.11b的例子中,n=6且m=10。地址转换需要经过以下步骤
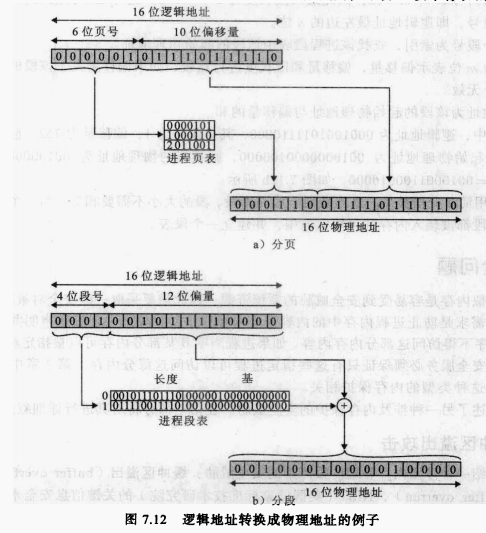
提取页号,即逻辑地址最左面的n位。
以这个页号为索引,查找该进程页表中相应的页框号k。
该页框的起始物理地址为k×2^m,被访问字节的物理地址是这个数加上偏移量。物理地址不需要计算,可以简单地把偏移量附加到页框号后面来构造物理地址。
在前面的例子中,逻辑地址为0000010111011110它的页号为1,偏移量为478。便设该页驻留在内存页框6(即二进制000110)中,则物理地址页框号为6,偏移量为478,物理地址为0001100111011110,如图7.12a所示。
分段






