InnoDB存储引擎
Innodb
- 支持事务,1.2版本支持全文索引
- 行锁设计,支持外键
- 文件结构:Mysql可以将每个InnoDB存储引擎的表单独存放到一个独立的ibd文件中(包括索引和数据),该引擎采用了聚集的方式,因此每张表的存储都是按主键的顺序进行存放,若没有显示(人为)地在表定义主键,InnoDB存储引擎会为每一行生成一个6字节的ROWID,并以此作为主键
- InnoDB通过使用多版本并发控制(MVCC)来获得高并发性,实现了四种隔离级别,默认为Reapeatable。
- 处理数据过程,提供插入缓冲,二次写,自适应哈希索引,预读等高性能,高可用功能。
MyISAM
- 不支持事务,表锁设计,支持全文索引
- 与其他存储引擎与众不同的是它的缓冲池只缓存索引文件,而不缓冲数据文件
- 文件结构:MyISAM存储引擎表由MYD,MYI组成,MYD存储数据文件,MYI存储索引文件,非聚集(分离)
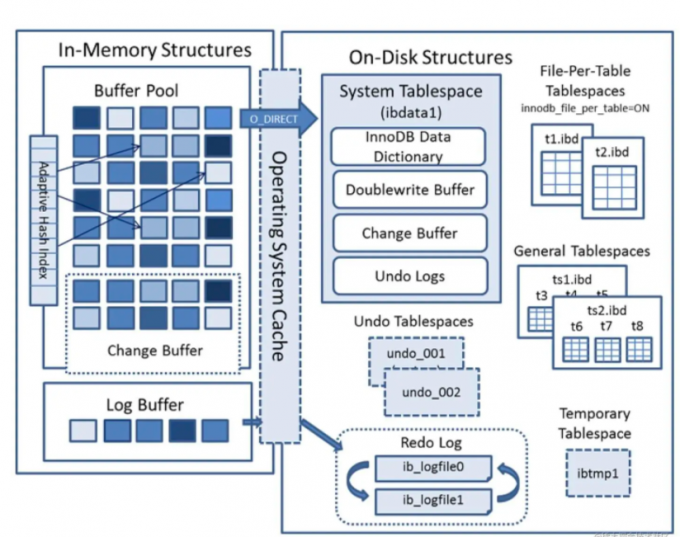
InnoDB体系结构
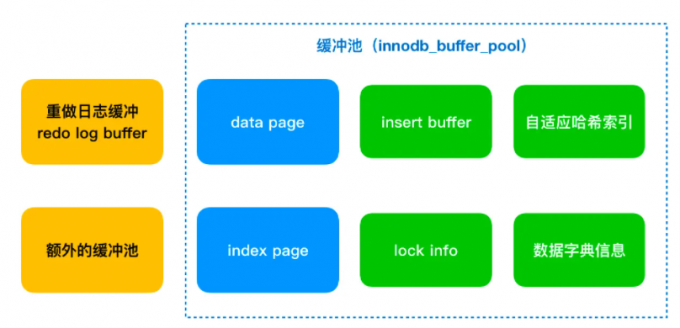
InnoDB存储引擎有多个内存块,可以认为这些内存块组成了一个大的内存池,负责维护如下工作:
- 维护所有进程/线程需要访问的多个内部数据结构
- 缓存磁盘上的数据,方便快读的读取,同时在对磁盘文件的数据修改之前在这里缓存
- 重做日志(redo log)缓冲
- ……
后台线程的主要作用是负责刷新内存池中的数据,保证缓冲池中的内存缓存的是最近的数据:
MasterThread:
主要负责将缓冲池中的数据异步刷新到磁盘,保证数据的一致性,包括脏页的刷新、合并插入缓冲、undo页的回收等
内存结构
InnoDB存储引擎是基于磁盘存储的,并将其中的记录方式按照页的方式进行管理,因此可以将其视为基于磁盘的数据库系统
由于CPU速度与磁盘速度之间的鸿沟,基于磁盘的数据库系统通常使用缓冲池技术来提高数据库的整体性能。
- 缓冲池:
简单来说就是一块内存区域,通过内存的速度来弥补磁盘速度较慢对数据库性能的影响
页的读取
首先将磁盘读到的页存放在缓冲池中(这个过程为“FIX”在缓冲池),下一次在读取相同的页,首先判断该页是否在缓冲池中,若在缓冲池中,则称该页在缓冲池中被命中,直接在缓冲池中读取该页,否则,读取磁盘上的页。
页的修改
首先修改缓冲池的页,然后在一定的频率刷新到磁盘上。这里需要注意的是,页从缓冲池刷新回磁盘的操作并不是在每次页的发生更新触发,而是通过一种称为CheckPoint的机制刷新回磁盘。
缓冲池中的LRU
数据库中的缓冲池是通过LRU算法进行管理的。即最频繁使用的页在LRU列表的前端,而最少使用的页在LRU列表的尾端。当缓冲池不能存放新读取到的页时,将首先释放LRU列表中尾端的页
在InnoDB存储引擎中,缓冲池的页大小默认为16KB。InnoDB存储引擎对传统的LRU算法做了一些优化:
你知道数据库缓冲池中的LRU-List吗?【图文】_小岑的博客_51CTO博客
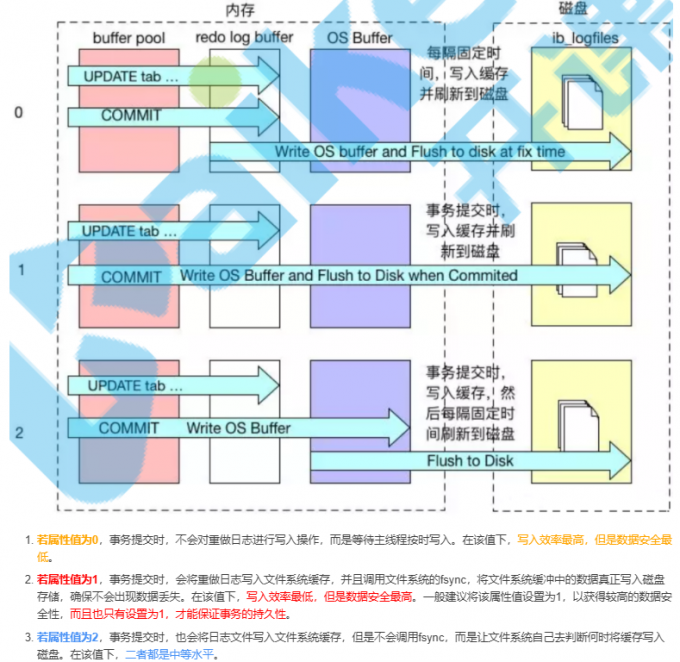
重做日志缓冲
- Master Thread每一秒会将从重做日志缓冲刷新到重做日志文件
- 每次事务的提交时会将重做日志缓冲刷新到重做日志文件
- 重做日志缓冲池小于1/2时,重做日志缓冲刷新到重新日志文件
CheckPoint技术 P33
倘若每一个页发生变化,就将新页的版本刷新到自盘,开销是十分大的
问题: 若当缓冲池将页的新版本刷新回磁盘时发生了宕机,数据就不能回复了
解决:为了避免数据丢失的问题,当今数据库系统普遍采取了 Write Ahead Log策略,即当事务(修改,插入,删除)提交时,先写重做日志,再修改页。当由于发生宕机而导致数据丢失时,通过重做日志来完成数据库的恢复。这也是事务ACID的D(持久性)的要求
CheckPoint(检查点)的目的是解决以下问题:
缩短数据库的恢复时间
当数据库发生宕机时,数据库不需要重做所有的日志,因为CheckPoint之前的页都已经刷新回磁盘,故数据库只需要对检查点以后的重做日志进行恢复,这样就大大缩短了恢复的时间
缓冲池不够用时,将脏页刷新到磁盘
缓冲池通过LRU算法进行管理,而当脏页(未刷新回磁盘的页)要被替换,淘汰时,需要强制执行CheckPoint,将脏页刷新回磁盘
重做日志不可用时,刷新脏页
CheckPoint类型
Sharp CheckPoint
Sharp CheckPoint发生在数据库关闭时,将所有的脏页都刷新回磁盘
Fuzzy CheckPoint(还分很多种,其中包括 MasterThread CheckPoint 每秒异步从缓冲池脏页刷新一定比例的页面回磁盘)
数据库在运行时,使用Fuzzy CheckPoint进行页的刷新,即只刷新一部分脏页,而不是刷新所有的脏页回磁盘
InnoDB关键特性 P45
插入缓冲(Insert Buffer)
这个名字可能会让人认为插入缓冲是缓冲池的一个组成部分,其实不然,InnoDB缓冲池中有InsertBuffer 信息固然不错,但是InsertBuffer和数据页一样,也是物理页的一个组成部分
对于非聚集索引的插入和更新操作,并不是每一次直接插入到索引页中,而是先判断插入的这个非聚集索引页是否在缓冲池中,若存在,直接插入;若不存在,则先放入InsertBuffer中,好似欺骗。数据库这个非聚集索引已经查到叶子节点,而实际没有,只是存放在另一个位置,等一定的频率和情况进行InsertBuffer和辅助索引页子节点的的merge操作
两次写
自适应哈希索引
异步IO
刷新邻接页
重做日志
(104条消息) MySQL重做日志(redo log)总结_weixiaohuai的博客-CSDN博客
(104条消息) MySQL重做日志缓冲 - Redo log Buffer_薛定谔的码的博客-CSDN博客
InnodDB数据页结构
P120
File Header(文件头)
Page Header (页头)
Infimun 和 Supremum Record
User Records(用户记录,即行记录)
Free Space(空闲空闲)
链表数据结构,在一条记录删除后,该空间会被加入到空闲链表中
Page Directory(页目录)
File Trailer(文件结尾信息)
检验页是否已经完整写入磁盘
分区表
p152
分区的过程是将一个表或索引分解为更小、更可管理的部分
Mysql数据库支持的分区类型为水平分区(同一表中不同行的记录分配到不同的物理文件中),并不支持垂直分区(同一表中不同列的记录分配到不同的物理文件中)
分区类型
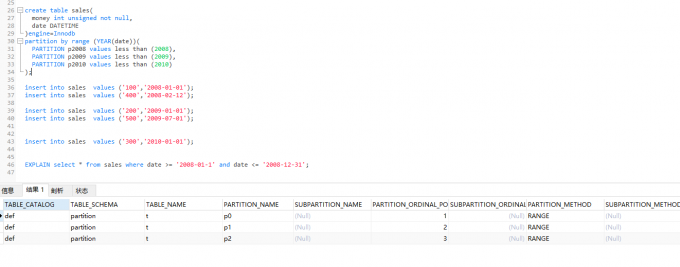
RANGE分区
行数据基于属于一个给定连续区间的列值被放入分区
LIST分区
LIST分区面向的是离散的值
HASH分区
根据用户自定义的表达式的返回值来进行分区,返回值不能为负数
KEY分区
根据MySQL数据亏提供的哈希函数来进行分区
RANGE分区
对于range分区的查询,优化器只能对YEAR(),TO_DAYS(),TO_SECONDES(),UNIX_TIMESTAMP()这类函数进行优化选择
一般RANGE分区主要用户日期类分区,例如对于销售表,按年分。
LIST分区
分区列为离散值,而非连续

不同存储引擎对于插入分区中的影响
p163
MyISAM
分区po(1,3,5,7,9)
分区p1(0,2,4,6,8)
对于如下插入语句
mysql > insert into values (1,2),(2,4),(6,10),(5,3);
MYISAM 会将(1,2),(2,4)成功插入表 ,而(6,10)(5,3)不会插入成功
InnoDB
还是一样的分区:
分区po(1,3,5,7,9)
分区p1(0,2,4,6,8)
对于如下插入语句
mysql > insert into values (1,2),(2,4),(6,10),(5,3);
InnoDB呈现的是:没有一条记录成功插入表
Hash分区
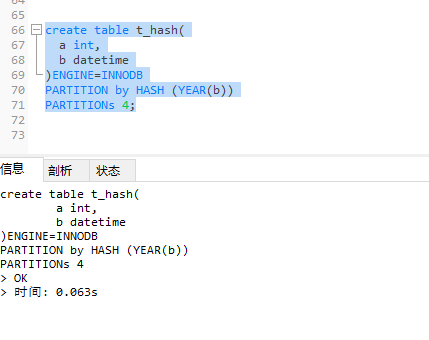
对于上述分区
若插入一条列b为2010-04-01的记录到表t_hash中,那么保存该条记录的分区如下:
MOD(YEAR (‘2010-04-01’),4)
= MOD(2010,4)
= 2
LINEAR HASH
KEY分区
类似HASH分区 ,利用MYSQL内部的哈希函数(HASH为人工定义的)
COLUMN分区
可以对字符串进行分区,日期也可以不用YEAR函数
可以直接
partition by range column(B)(
partition p0 values less than (‘2009-01-01’),
)
MVCC,快照读,当前读
【MySQL】当前读、快照读、MVCC - wwcom123 - 博客园 (cnblogs.com)
深入剖析MySQL innodb事务与MVCC实现原理 - sunsky303 - 博客园 (cnblogs.com)
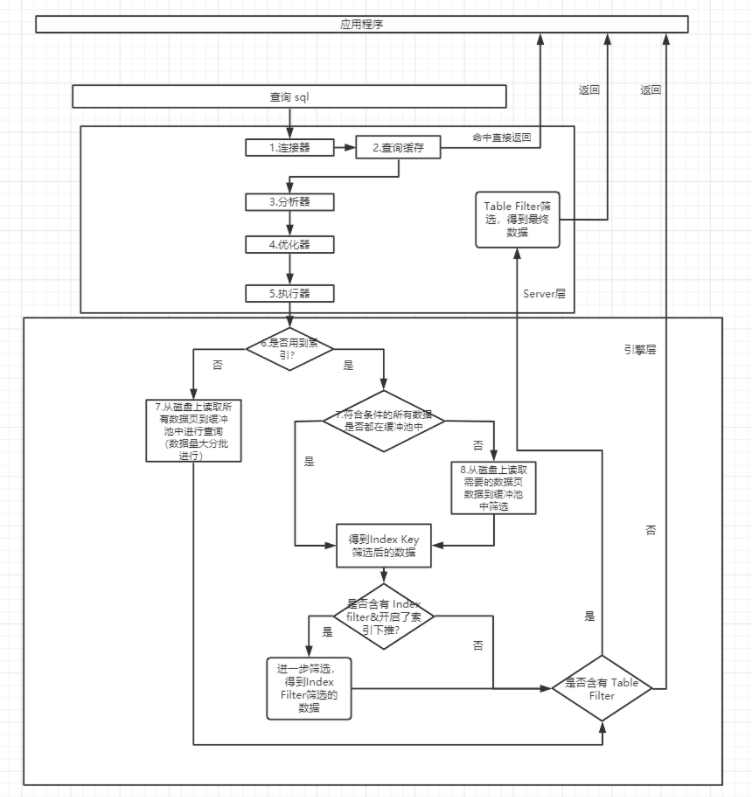
一条SQL执行过程
写操作

读操作