ConcurrentHashMap
ConcurrentHashMap属性
// 最大容量,同 hashmap |
我们要注意 sizeCtl 属性!在判断状态会使用到
内部类Node
和 HashMap 一样的。但是注意这个地方采用了 volatile 关键字。
static class Node<K, V> implements Map.Entry<K, V> { |
内部类TreeNode
直接继承了 Node 节点 所以相比 HashMap 中的 TreeNode 少了 before 和 after 属性。他的方法比较少主要是因为红黑树已经不用这个数据结构了而是采用的 TreeBin ,但是它存在是因为在转成红黑树的时候是先把 Node 封装成 TreeNode 然后再封装到 TreeBin 中的。
static final class TreeNode<K, V> extends Node<K, V> { |
内部类TreeBin
//作者注释 |
主要方法
构造函数
// 空方法,注释说会创建大小为 16 的数组,估计是延时加载 在 put 里面 |
get()方法
get 方法就和 HashMap 差不多,因为发现他连锁都没有加,按照以前的那个套路,首先计算 hash 然后找到数组的节点,看第一个是不是,然后看是否是红黑树或者是链表,它们采用了顺序查找,就 while 循环。
那么我们需要考虑一下为什么不需要加锁,难道我们在读元素的时候同时有别的线程在写不会出现安全问题?举个例子,当我们在遍历一个链表寻找元素的时候刚好有线程在链表的结尾做插入操作,要么我们读到链表结尾的时候,写线程没有更新链表的结尾元素那么我们就认为读先于写也就没有安全问题,因为我们在读的时候不会发现尾节点指针正好发生变化,简单来说写线程的节点指针操作是原子的,对其他线程也是可见的,这时你应该清楚为什么链表的 next 是 volatile 。
public V get(Object key) { |
put()/putVal()方法
最重要的,put 方法。这个方法里面直接调用了 putVal ,其实 putVal 的逻辑有点复杂,就单看代码来说,代码量还是比较大的。 那么我们先介绍一下 putVal 的大概的逻辑然后再看代码。
- 首先就判断了 key 和 value 不能为空的情况,一开始觉得还挺奇怪的 HashMap 就允许 null 作为键值为什么 ConcurrentHashMap 却不行,这里我查了一下这段源码作者 Doug Lea 的解释是 “ 在普通的非并发的 HashMap 中我们可以存放 null 然后至于这个地方是否是真的为 null 还是由于键不存在呢,我们可以采用
containsKey来判断。但是在并发情况下在调用方法时可能会发生引用关系的变化导致歧义 ”。感觉还是有点抽象难懂,我自己的理解就是:当我们调用map.get(key)时候返回null的时候假如根本不存在这个key,但是我们由于不清楚这个地方的值到底是null还是这个key根本不存在,我们就会调用containsKey来检查,但是在这个时间间隙中有其他线程往里面放了一个key -> null导致我们检测的结果是有这个键值对,从而误判! - 然后我们前面也提到了,在构造方法中没有任何初始化表的操作,所以说我们在 putVal 中如果判断到表空,就需要进行初始化工作。这个初始化调用了一个
initTable()这个方法稍后专门分析。 - 接着就是利用 hash 值来获取数组的索引了,首先还是判断那个对应的位置有没有元素,如果没有的话就简单了,采用 CAS 操作添加一个新节点此时添加工作就完成了可以返回了。如果不是这种情况就继续往下看。
- 我们看头结点的 Hash 值是否是
MOVED,如果是就说明当前的表正在进行transfer我们就让当前线程去帮助transfer。现在没看懂没关系等看到transfer方法的时候就知道为什么了。 - 否则的话就是一个正常的链表或者红黑树了,这时候我们就和 HashMap 一样,如果是一个链表我们就遍历链表,然后遇到相同的 key 进行 value 的替换,否则插入到链表的结尾。 如果是一个红黑树就执行红黑树的插入操作。 注意这个操作是在同步代码块中进行的,因为我们不能保证多线程的修改安全,但是这个代码块的锁是头结点,也就是数组有多少元素我们就可以同时操作多少把锁,这样并发数就是数组的长度。而前面定义的并发数没有实质的作用。
- 最后由于我们插入了一个节点需要判断一下当前的节点数是不是大于转红黑树的阈值(默认为8)。是则调用
treeifyBin,这个方法也比较复杂,待会专门来说。
public V put(K key, V value) { |
initTable()方法
上面已经分析了关于 put 方法,我们还有两个问题没有解决,一个是初始化表,另外一个是转成红黑树,先分析表的初始化。那先回顾一下 HashMap 他是采用同样的延时加载然后在 resize 方法中进行了表的初始化工作。也就是 HashMap 的 resize 方法同时进行了初始化和扩容以及迁移的工作,在 ConcurrentHashMap 中划分的更细致,初始化就只进行初始化,因为他是并发的要考虑到更多。 一样的,我们先分析一下大致的思路。
- 首选先需要看是不是有别的线程在进行初始化,如果是我们就不要进行初始化了让出 cpu 资源让别的线程继续初始化。这个如何判断别的线程是否在初始化?就涉及到了前面的
sizeCtl属性,当他是 -1 的时候就说明在进行表的初始化工作。 - 显然当别的线程没有初始化,当前线程就要初始化。并且不让别的线程进行争夺,就把
sizeCtl用 CAS 置为 -1,并开始初始化。 - 初始化的工作有两个,一是 new 一个容量为 16 的新数组,其次设置扩容的阈值也就是
sizeCtl的值,设置好了也说明初始化完毕。
private final Node<K, V>[] initTable() { |
treeifyBin()方法
接下来就要看看链表转红黑树的操作了。
这个操作没有像我想的那样直接进行转树的操作,而是做了一系列的判断。
当链表长度大于等于 16 但数组长度小于 64 时,需要进行一次扩容操作,扩容操作又委托给了 tryPresize 扩容是预计扩容到原来的两倍。注意区分链表长度和数组长度不要弄混了!!!
接下来就是真正的链表转成树的操作了。
private final void treeifyBin(Node<K, V>[] tab, int index) { |
tryPresize()方法
继续分析上面遗留下来的问题,扩容操作。
- 首先判断表是否为空,空则进行初始化,代码同
initTable - 如果
3*tableSize+1 < 扩容阈值就不扩容,这个情况基本不会发生。 - 将
sizeCtl设置为下次要进行扩容的阈值,然后进行transfer,这个方法里面才是真正的将数组大小扩充为原来的两倍并且进行数据迁移。
整体看起来还是以前的 HashMap 的套路,他的 resize 进行初始化、扩容、数据迁移。而这里把这三步拆成了三个方法分别来做,以保证高并发。
private final void tryPresize(int size) { |
transfer()方法
transfer 是这个类中最麻烦也是最精巧的一个方法,还是先说思路再阅读代码。
- 如果当前的
nextTab是空,也就是说需要进行扩容的数组还没有初始化,那么初始化一个大小是原来两倍的数组出来,作为扩容后的新数组。 - 我们分配几个变量,来把原来的数组拆分成几个完全相同的段,你可以把他们想象成一个个大小相同的短数组,每个短数组的长度是
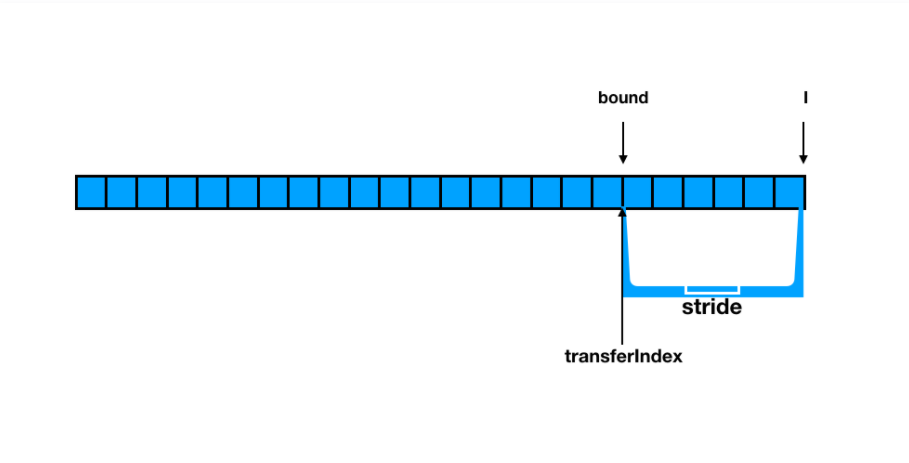
stride。 - 我们先取最后一个短数组,用
i表示一个可变的指针,可指向短数组的任意一个位置,最开始指向的是短数组的结尾。bound表示短数组的下界,也就是开始的位置。也就是我们在短数组选择的时候是采用从后往前进行的。 (从后往前!!!) - 然后使用了一个全局的属性
transferIndex(线程共享),来记录当前已经选择过的短数组和还没有被选择的短数组之间的分隔。 - 那么当前的线程选择的这个短数组其实就是当前线程应该进行的数据迁移任务,也就是说当前线程就负责完成这一个小数组的迁移任务就行了。那么很显然在
transferIndex之前的,没有被线程处理过的短数组就需要其他线程来帮忙进行数据迁移,其他线程来的时候看到的是transferIndex那么他们就会从transferIndex往前数stride个元素作为一个小数组当做自己的迁移任务。
好,现在可能感觉有点乱,来总结一下。当前的数组的迁移被分为很多的任务包,每一个任务包中有 stride 个元素,然后这些任务包需要被从后往前的分配给不同的线程。分配过程依赖于共享的全局变量 transferIndex 。这样做的原因就是为了高并发,不得不佩服写这个类源码的大师! 下面用一张图在来总结一下上面所说的内容。
现在线程收到自己的任务包了,肯定就需要进行数据迁移的工作了。迁移工作就比较简单了,由于是需要对链表或红黑树节点进行操作,必须要对过程同步,锁还是头结点。进行节点迁移的时候,就是和 HashMap 一样,把原来的链表和树拆成两部分,分别放到 i 和 i+n (相同位置)上。
我们还是主要看链表的拆分,采用的看 hash 值的某一特定位是 0 还是 1 来决定放在哪个位置,节点采用的头插法,也就是部分的节点的顺序是反的。为什么说部分是反的?那是因为他在里面一大段代码都在干一件事,去找原链表的最后一段特定位相同的完整序列保持顺序不变。这个比较难说清楚还是用一张图来说明一下。
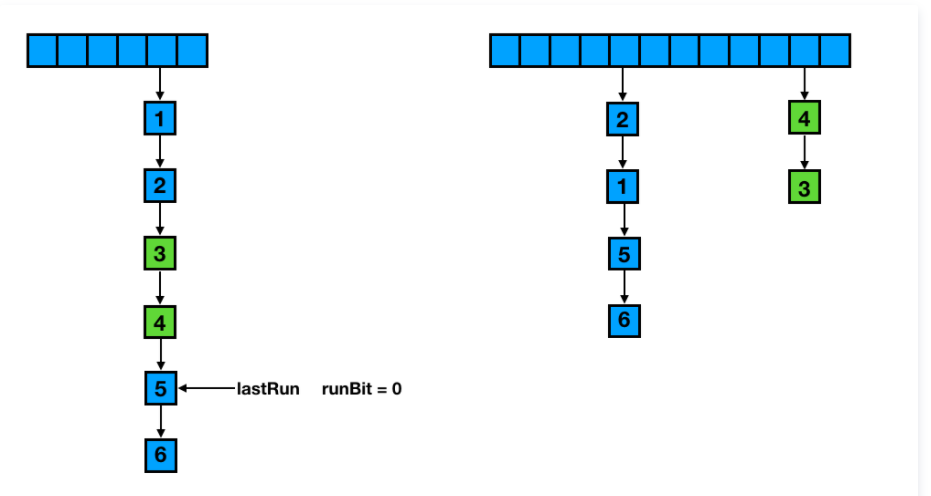
ForwardingNode
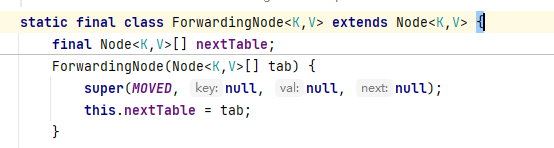
接下来贴源码
/ 把节点拷贝到新数组里面 |
helpTransfer()方法
这个方法主要是让其他线程在对表做操作的时候刚好遇到了,表在扩容,数据迁移。就让这些线程帮助完成这个数据迁移,也就是去领取 transfer 中的数据迁移的任务包。
//1. putVal 当有 MOVED 节点的时候 2.replaceNode 也就是在 remove 中 当有 MOVED 节点的时候 |
总结
首先这个类很多操作和
HashMap是类似的,但是麻烦就麻烦在锁分离技术和并发处理底层还是采用的
数组+链表+红黑树来实现的,但是红黑树的TreeNode改成了TreeBin里面有很多 CAS (Compare And Swap)操作,比如说
unsafe.compareAndSwapInt(this, valueOffset, expect, update)意思是如果valueOffset位置包含的值与expect值相同,则更新valueOffset位置的值为update,并返回true,否则不更新,返回false。不仅仅是 CAS 还有一些重量级的锁。也就是
synchronized代码块用来保证操作同一数组元素下的节点的一致性,后面会看到。


